muestreo de manera uniforme al azar de una unidad de n-dimensional simplex es la forma elegante de decir que desea n números aleatorios tal queMuestra uniformemente al azar de una unidad simple de n dimensiones
- son todas libres negativo,
- suman a uno, y
- cada posible vector de n números no negativos que sumen a uno son igualmente probables.
En el caso n = 2, quiere muestrear uniformemente del segmento de la línea x + y = 1 (es decir, y = 1-x) que está en el cuadrante positivo. En el n = 3 caso de que esté muestreo de la parte en forma de triángulo del plano x + y + z = 1 que está en el octante positivo de R3:
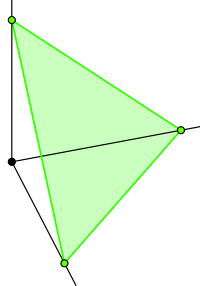
(Imagen de http://en.wikipedia.org/wiki/Simplex.)
Tenga en cuenta que elegir n números aleatorios uniformes y luego normalizarlos para que sumen a uno no funciona. Terminas con un sesgo hacia números menos extremos.
Del mismo modo, elegir n-1 números aleatorios uniformes y luego tomar la enésima para ser uno menos la suma de ellos también introduce un sesgo.
Wikipedia ofrece dos algoritmos para hacer esto correctamente: http://en.wikipedia.org/wiki/Simplex#Random_sampling (Aunque el segundo momento, sólo afirma que es correcta en la práctica, no en la teoría que espero que limpiar eso o aclarar que cuando entiendo esto mejor.. Inicialmente metí en un "ADVERTENCIA: documento de tal y tal afirma que lo siguiente es incorrecto" en esa página de Wikipedia y otra persona lo convirtió en la advertencia "funciona solo en la práctica")
Finalmente, la pregunta: ¿Cuál considera que es la mejor implementación del muestreo símplex en Mathematica (preferiblemente con confirmación empírica de que es correcto)?
preguntas relacionadas
{kind=link}
Parece que hay varios métodos que funcionan bien: la única diferencia real es la velocidad y la capacidad de lectura. ¿Cuál es su criterio aparte de 'el mejor'? – zdav
¡La velocidad y la legibilidad son excelentes criterios! Concisión podría ser otra. Si tiene una implementación que tiene algo que ofrecer, continúe y publíquela como respuesta. – dreeves
Creo que la advertencia de Wikipedia es un poco falsa; los autores del artículo citado se preocupan por la uniformidad perfecta para una * versión discretizada * de este problema. El segundo algoritmo descrito es perfectamente correcto desde el punto de vista matemático, y debería funcionar bien en la práctica si estás dispuesto a considerar el 'número de coma flotante aleatorio de [0, 1]' como una aproximación lo suficientemente buena para 'real aleatorio número de [0, 1] '. –