26
R tiene una función útil pairs que proporciona una buena matriz de gráficos de conexiones por pares entre variables en un conjunto de datos. El gráfico resultante tiene una apariencia similar a la siguiente figura, copiado de this blog post:matplotlib analógico de pares de R '
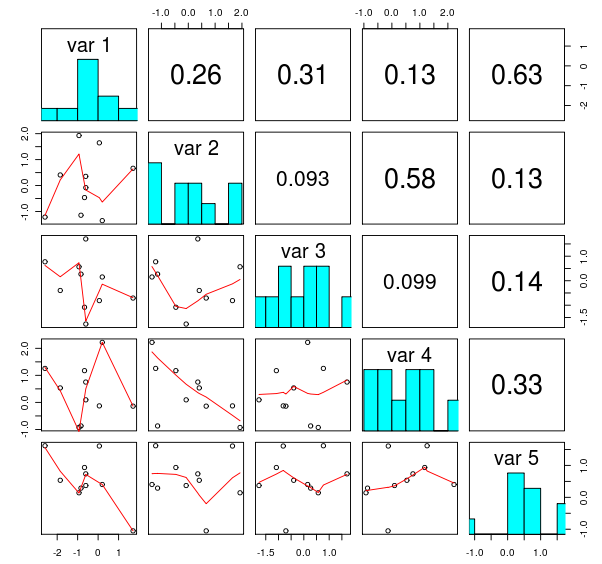
¿Hay alguna lista para utilizar la función basada en matplotlib de pitón? He buscado en gallery, pero no he podido encontrar nada que se parezca a lo que necesito. Técnicamente, esto debería ser una tarea simple, pero el manejo adecuado de todos los casos posibles, etiquetas, títulos, etc. es muy tedioso.
ACTUALIZACIÓN vea a continuación mi respuesta con una aproximación rápida y sucia.

Seaborn tiene esto, ver: http://seaborn.pydata.org/generated/seaborn. pairplot.html –