Digamos que tengo una lista de enteros, donde cada elemento es un número del 1 al 20. (Eso no es lo que estoy tratando de ordenar)¿Qué tipo de clasificación es esta?
Ahora, tengo una serie de "operaciones", donde cada funcionamiento:
- Elimina ciertos números (conocido) de la lista
- yAñade ciertos otros números (conocidos) a la lista
- y es incapaz de manejar la lista si contiene ciertos números (conocidos) al comienzo de la operación - llamar a estos Prevenir
Editar: Puede haber cero o más números en cada uno de Añade , Elimina y Evite para cada operación, y cada número puede aparecer cero o más veces en cada grupo para alguna operación. Para cualquier operación dada, Añade y Elimina son disjuntos, Prevenir y Elimina son disjuntos, pero Añade y Prevenir se pueden solapar.
Quiero ordenar la matriz de las operaciones de manera que para cada operación:
- Si la operación tiene Prevenir artículos, que se coloca después de una operación que Elimina esos números. Si no inmediatamente después, no puede haber una operación Agrega que agrega esos números entre los últimos Elimina y Previene.
- Si la operación Elimina elementos, todas las operaciones que Agregue cualquiera de esos elementos se coloca delante de ella.
En el caso de una dependencia circular, la cadena de operaciones deberían eliminar tantos números como sea posible y informarme que no podía eliminar todos los números.
¿Hay algún nombre/implementación para este tipo de algoritmo que supere al que tengo a continuación?
Agregado 8/23: La recompensa es para cubrir los requisitos de clasificación teniendo en cuenta tanto los opcodes (juego de estructuras) y InstructionSemantics (conjunto de indicadores de bits de una enumeración).
añadió más tarde 8/23: hice un 89: mejora del rendimiento 1 por heurísticamente preclasificación la matriz de origen. Ver mi respuesta actual para más detalles.
namespace Pimp.Vmx.Compiler.Transforms
{
using System;
using System.Collections.Generic;
using System.Reflection.Emit;
internal interface ITransform
{
IEnumerable<OpCode> RemovedOpCodes { get; }
IEnumerable<OpCode> InsertedOpCodes { get; }
IEnumerable<OpCode> PreventOpCodes { get; }
InstructionSemantics RemovedSemantics { get; }
InstructionSemantics InsertedSemantics { get; }
InstructionSemantics PreventSemantics { get; }
}
[Flags]
internal enum InstructionSemantics
{
None,
ReadBarrier = 1 << 0,
WriteBarrier = 1 << 1,
BoundsCheck = 1 << 2,
NullCheck = 1 << 3,
DivideByZeroCheck = 1 << 4,
AlignmentCheck = 1 << 5,
ArrayElementTypeCheck = 1 << 6,
}
internal class ExampleUtilityClass
{
public static ITransform[] SortTransforms(ITransform[] transforms)
{
throw new MissingMethodException("Gotta do something about this...");
}
}
}
Editar: Por debajo de esta línea es información básica sobre lo que estoy haciendo en realidad, en caso de que la gente se pregunta por qué estoy pidiendo esto. No cambia el problema, solo muestra el alcance.
Tengo un sistema que lee en una lista de elementos y lo envía a otro "módulo" para su procesamiento. Cada elemento es una instrucción en mi representación intermedia en un compilador, básicamente un número de 1 a ~ 300 más una combinación de aproximadamente 17 modificadores disponibles (enumeración de banderas). La complejidad del sistema de procesamiento (ensamblador de código de máquina) es proporcional a la cantidad de entradas únicas posibles (número + indicadores), donde tengo que codificar manualmente cada manejador individual. Además de eso, tengo que escribir al menos 3 sistemas de procesamiento independientes (X86, X64, ARM): la cantidad de código de procesamiento real que puedo usar para múltiples sistemas de procesamiento es mínima.
Al insertar "operaciones" entre la lectura y el procesamiento, puedo asegurarme de que ciertos elementos nunca aparecen para el procesamiento; esto lo hago expresando los números y/o indicadores en términos de otros números. Puedo codificar cada "operación de transformación" en una caja negra describiendo sus efectos, lo que me ahorra una tonelada de complejidad por operación. Las operaciones son complejas y únicas para cada transformación, pero mucho más sencillas que el sistema de procesamiento. Para mostrar cuánto tiempo ahorra, una de mis operaciones elimina por completo 6 de las banderas al escribir sus efectos deseados en términos de aproximadamente 6 números (sin banderas).
Para mantener las cosas en el recuadro negro, quiero que un algoritmo de ordenamiento tome todas las operaciones que escribo, ordene que tengan el mayor impacto y me informen sobre el éxito que tuve en simplificar los datos que eventualmente llegar al (los) sistema (s) de procesamiento. Naturalmente, me estoy dirigiendo a los elementos más complejos en la representación intermedia y simplificándolos a la aritmética de puntero básico donde sea posible, que es el más fácil de manejar en los ensambladores. :)
Con todo lo dicho, agregaré otra nota. Los efectos de operación se describen como "efectos de atributo" sobre la lista de instrucciones. En general, las operaciones se comportan bien, pero algunas de ellas solo eliminan los números que caen después de otros números (como eliminar los 6 que no siguen un 16). Otros eliminan todas las instancias de un número particular que contiene ciertos indicadores. Los manejaré más tarde, DESPUÉS de resolver el problema básico de la garantía de agregar/quitar/prevenir enumerado anteriormente.
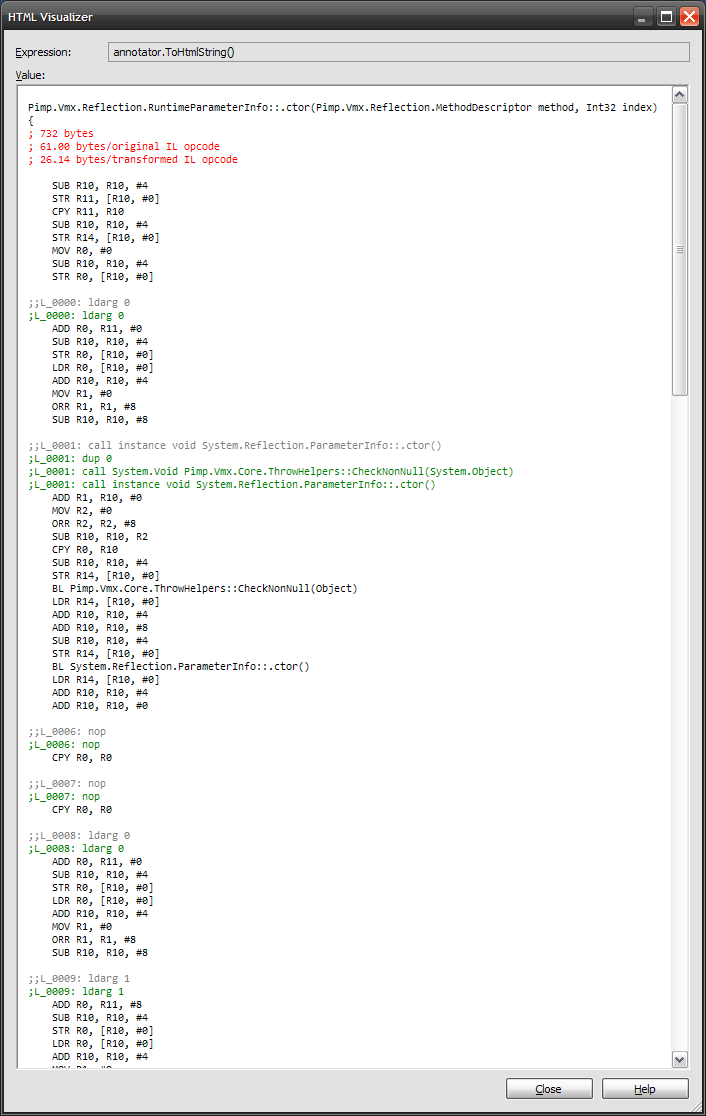
Agregado 8/23:In this image, se puede ver una instrucción call (gris) que tenían InstructionSemantics.NullCheck fue procesado por el RemoveNullReferenceChecks transformar a quitar la bandera semántica a cambio de añadir otra llamada (sin semántica asociada al agregado llama tampoco). Ahora el ensamblador no necesita comprender/manejar InstructionSemantics.NullCheck, porque nunca los verá. Sin criticar el código ARM - it's a placeholder for now.
{kind=link}
@John, las operaciones múltiples pueden agregar y/o quitar cada artículo. Necesito la última instancia de * Eliminar * después de la última instancia de * Agregar *. –
@John: verifique mi edición debajo de las descripciones de los grupos. –
¡Ah, eso hace una gran diferencia! Eliminaré mis otros comentarios. –