Estoy escribiendo un algoritmo en OpenCL en el que necesitaría que cada unidad de trabajo recuerde una porción justa de datos, digamos algo entre long[70] y long[200] más o menos por kernel.memoria física en dispositivos AMD: local vs privado
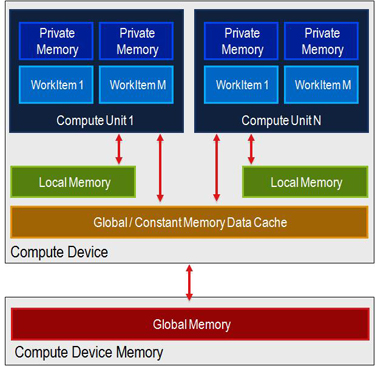
Los dispositivos AMD recientes tienen memoria 32 KiB __local, que es (para la cantidad dada de datos por kernel) suficiente para almacenar la información de 20-58 unidades de trabajo. Sin embargo, por lo que entiendo de la arquitectura (y especialmente de this drawing), cada núcleo de sombreador también tiene una cantidad dedicada de memoria privada. Sin embargo, no encuentro su tamaño.
{kind=link}
¿Alguien puede decirme cómo saber cuánta memoria privada tiene cada kernel?
Tengo mucha curiosidad sobre el HD7970, ya que planeo comprar algunos de estos pronto.
Editar: Problema resuelto, la respuesta es here en el apéndice D.
No creo que la memoria privada esté dedicada por núcleo: se correlaciona con el archivo de registro, que es por recurso de unidad de cómputo. Cada elemento de trabajo obtiene registros asignados desde el archivo de registro de la unidad de cómputo, cuántos son necesarios determina el número de frentes de onda en vuelo en cualquier instante dado. – talonmies
Del famoso dibujo visto en todas partes http://www.codeproject.com/KB/showcase/Memory-Spaces/image001.jpg Llegué a la conclusión de que la memoria privada es físicamente diferente de la memoria local __, ¿no? – user1111929
Sí, son físicamente diferentes. La memoria privada se asigna al archivo de registro de la unidad informática, la memoria local para calcular la memoria compartida a nivel de unidad en la mayoría de los dispositivos AMD modernos. Algunas primeras GPU compatibles con OpenCL no tenían en la memoria compartida, y la memoria local era solo SDRAM. Tampoco es por núcleo, y cuánto usa por artículo de trabajo para grupos privados y por grupo de trabajo para efectos locales el número de frentes de onda concurrentes que se ejecutan por unidad de cómputo. – talonmies