He leído algunos libros y artículos sobre la red neuronal convolucional, parece que entiendo el concepto, pero no sé cómo ponerlo arriba como en la imagen de abajo: alt text http://what-when-how.com/wp-content/uploads/2012/07/tmp725d63_thumb.pngRed neuronal convolucional - ¿Cómo obtener los mapas de características?
{kind=link}
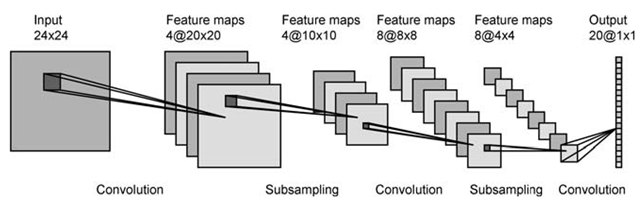
de 28x28 píxeles normalizado ENTRADA obtenemos 4 mapas de características de tamaño 24x24. pero, ¿cómo conseguirlos? cambiar el tamaño de la imagen de ENTRADA? o realizar transformaciones de imagen? pero que tipo de transformaciones? o cortando la imagen de entrada en 4 pedazos de tamaño 24x24 por 4 esquinas? No entiendo el proceso, para mí parece que cortan o cambian el tamaño de la imagen a imágenes más pequeñas en cada paso. por favor ayuda gracias.
¿Podría enumerar los libros/artículos que lee para Convolutional Neural Network? Gracias por adelantado. – lmsasu
Es de Neural Networks and Learning Machines, tercer libro de edición –
Estaba confundido también, esta convolución es en realidad la parte más importante (de ahí el nombre 'convolucional NN'), pero la mayoría de las personas parecen centrarse en explicar cómo funciona la CNN, e ignore la parte de "cómo obtener los mapas de características". Estaba confundido (y enojado, también) hasta que encontré este sitio web: http://www1.i2r.a-star.edu.sg/~irkhan/conn2.html Explica todo en inglés sencillo. –