6
He tenido la intención de actualizar un poco mi conocimiento de las estadísticas. Un área donde parece que las estadísticas serían útiles es en el código de creación de perfiles. Digo esto porque parece que la creación de perfiles casi siempre implica que trate de extraer cierta información de una gran cantidad de datos.¿Qué conceptos de estadísticas son útiles para el perfil?
¿Hay algún tema en las estadísticas que pueda mejorar para obtener una mejor comprensión de la salida del generador de perfiles? Puntos de bonificación si puede dirigirme a un libro u otro recurso que me ayude a comprender mejor estos temas.
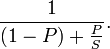
Eso es realmente en última instancia cómo lo hago, y es probable que tengas razón. Aún así, me gustaría obtener más información acerca de las estadísticas, y este parece ser un buen lugar para probar y hacerlo práctico para hacerlo. –
++ Neil tiene razón, aunque principalmente miro en el nivel de la línea, no en el nivel de la función. (Y, Neil, espero que por "porcentaje de tiempo" quieras decir "tiempo total", no "tiempo propio", y espero que quisieras "tiempo de reloj de pared", no solo de CPU, porque a medida que el software aumenta, el tiempo pierde se vuelve cada vez más debido a llamadas de función innecesarias, y algunas de ellas hacen E/S). –