A question that I answered me hizo pensar:detalles de implementación de expresiones regulares
Cómo son expresiones regulares implementados en Python? ¿Qué tipo de garantías de eficiencia hay? ¿La implementación es "estándar" o está sujeta a cambios?
Pensé que las expresiones regulares se implementarían como DFA, y por lo tanto eran muy eficientes (requiriendo como máximo un escaneo de la cadena de entrada). Laurence Gonsalves planteó un punto interesante de que no todas las expresiones regulares de Python son regulares. (Su ejemplo es r "(a +) b \ 1", que coincide con cierta cantidad de a's, a b, y luego con el mismo número de a's que antes). Esto claramente no se puede implementar con un DFA.
Entonces, para reiterar: ¿cuáles son los detalles de implementación y las garantías de las expresiones regulares de Python?
También sería bueno si alguien pudiera dar algún tipo de explicación (a la luz de la implementación) sobre por qué las expresiones regulares "cat | catdog" y "catdog | cat" llevan a diferentes resultados de búsqueda en la cadena " catdog ", como se menciona en el question that I referenced before.
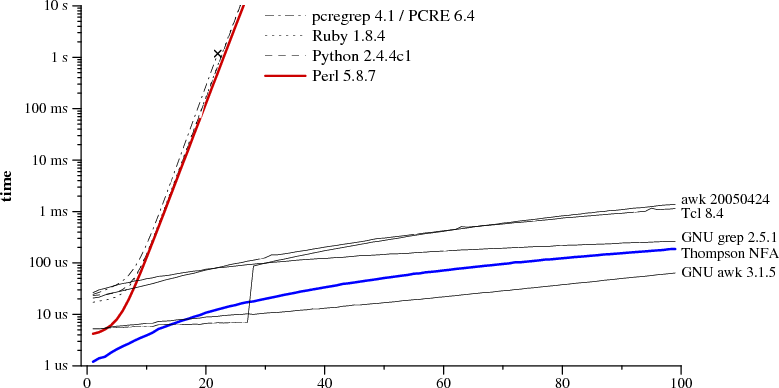
Las implementaciones de expresiones regulares actuales tienen muchas más características que las que describe la definición clásica de expresiones regulares. – Gumbo
@Gumbo: De hecho lo hacen ... esta es una de las razones de mi pregunta. Tengo curiosidad sobre una implementación específica porque realmente no es seguro asumir que se usa un DFA (debido a estas características adicionales). – Tom
Usa la fuente, Luke (http://svn.python.org/view/python/trunk/Lib/re.py?view=markup). En realidad parece bastante bien documentado. –