Parece haber varias opciones disponibles para programas que manejan grandes cantidades de conexiones de socket (como servicios web, sistemas p2p, etc.).¿Cómo manejar con mayor eficiencia un gran número de descriptores de archivos?
- Genera una hebra separada para controlar las E/S de cada socket.
- Utilice la llamada al sistema select para multiplexar las E/S en un único hilo.
- Utilice la llamada al sistema poll para multiplexar la E/S (reemplazando la selección).
- Use las llamadas al sistema epoll para evitar tener que enviar repetidamente sockets fd a través de los límites del usuario/sistema.
- Genera una serie de subprocesos de E/S que multiplexan un conjunto relativamente pequeño de la cantidad total de conexiones que usan la API de sondeo.
- Según el n. ° 5, excepto que utiliza la API epoll para crear un objeto epoll separado para cada subproceso de E/S independiente.
En una CPU multinúcleo, esperaría que el # 5 o el # 6 tuvieran el mejor rendimiento, pero no tengo datos duros que respalden esto. Buscando en la web apareció this página que describe las experiencias de los enfoques de prueba del autor # 2, # 3 y # 4 anteriores. Lamentablemente, esta página web parece tener alrededor de 7 años de antigüedad y no se encuentran actualizaciones recientes obvias.
Entonces mi pregunta es ¿cuáles de estos enfoques tienen las personas que son más eficientes y/o hay otro enfoque que funciona mejor que cualquiera de los enumerados anteriormente? Se apreciarán las referencias a gráficos de la vida real, libros blancos y/o grabaciones disponibles en la web.
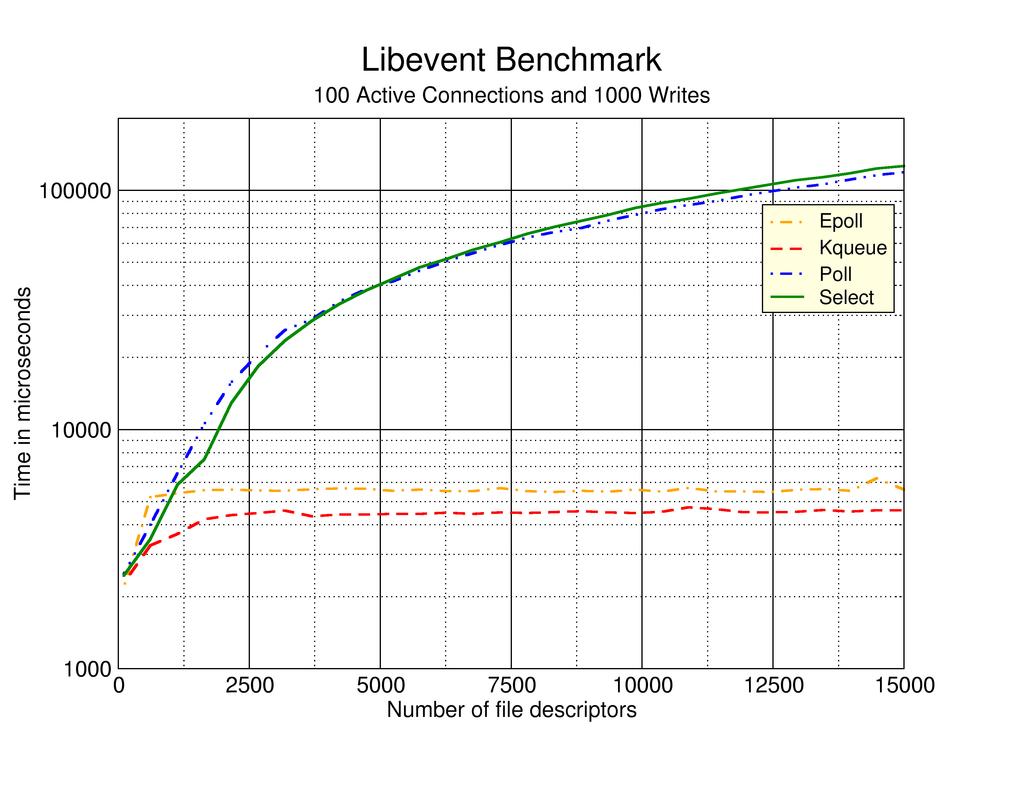 .
.
Creo que este es un problema resuelto y la respuesta está aquí - http://www.kegel.com/c10k.html – computinglife